데이터 이동 없이 AI 모델 개발…수익 발생하면 국민에 배당
[프레스나인] K-MELLODDY(연합학습 기반 신약개발 가속화 프로젝트) 사업단 김화종 단장이 신약개발을 위한 AI 개발에 국민의 건강보험·진료·유전체 데이터를 활용해 AI 예측 모델을 개발하고, 이를 통해 수익이 발생하면 국민에게 배당하는 '국민신약배당' 정책을 제안했다.

김화종 단장은 11일 오전 온라인을 통해 정책 제안 설명회를 개최, 해당 정책에 대한 설명과 함께 이에 대한 공론화가 필요하다는 입장을 밝혔다.
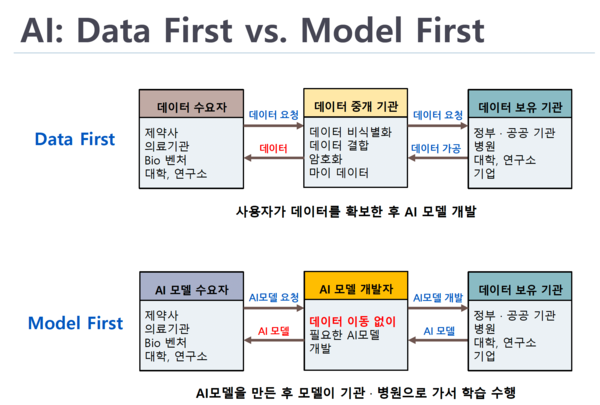
김화종 단장의 설명에 따르면 연합학습 기반 AI 모델은 데이터 이동 없이 AI 모델을 개발할 수 있다는 장점이 있다.
기존의 '데이터 퍼스트(Data First)' 방식의 경우 데이터 수요자가 데이터를 확보한 뒤 AI 모델을 개발했지만, '모델 퍼스트(Model First)' 방식은 AI 모델을 먼저 개발한 뒤 데이터를 보유한 기관이나 병원 등으로 모델을 이동해 학습시키게 된다.
모델 퍼스트 방식으로 접근하면 데이터의 이동이 필요 없고, 따라서 데이터 유출에 대한 우려 없이 AI 모델을 개발할 수 있다는 설명이다.
이러한 모델 퍼스트 방식으로 AI 모델을 개발하게 되면 다양한 실세계 데이터(Real-World Data)를 학습에 사용할 수 있어 성능이 우수한 AI 모델을 확보할 수 있다.
특히 우리나라의 경우 고품질 데이터라 할 수 있는 건강보험 데이터와 다양한 임상시험 데이터를 보유하고 있는 만큼 이를 활용하면 뛰어난 수준의 AI 모델을 개발할 수 있을 것으로 기대된다.
목적에 따라 AI 모델을 개발해 학습을 시키는 만큼 데이터 표준화에 대한 부담도 줄어들게 된다.
따라서 임상·공공 바이오 데이터를 AI 신약개발에 효과적으로 활용하는 기술과 제도를 도입하자는 것으로, 이렇게 개발한 AI 기술로 산업 수익을 창출하고, 그 수익을 국민과 공유하는 선순환구조를 만들자고 제안한 것이다.
김화종 단장은 "이 사업은 정부 주도로 추진해야 할 사업으로 K-MELLODDY 사업단이나 한국제약바이오협회가 하겠다는 것이 아니다"라며 "정부 부처와 구체적인 논의나 협의된 것이 아니라 정책을 제안하려는 것"이라고 말했다.
이어 "외국의 경우 비슷한 사례가 있기는 하지만, 데이터 자체에 가격을 지불하는 등의 방식으로 차이가 있다"면서 "데이터를 상품으로 보고 거래하는 것이 아니라 공공재로 보고 이를 이용한 수익을 공익화하자는 것"이라고 덧붙였다.
끝으로 "첫째로 데이터의 원천 제공자인 국민의 동의를 얻는 것이 가장 중요하다. 그러려면 보상이 필요하다"며 "데이터 구축·관리 기관인 병원 및 공공기관의 연구 확대, 책임 면제, 참여 시 인센티브 정책도 함께 필요하다. 오늘 설명회가 이러한 논의의 시작"이라고 전했다.